I. Introduction
Hate speech and toxicity has become increasingly prevalent on Twitter and related social media networks (SMNs). Hate speech and toxicity has been linked to issues including polarizing online citizens on COVID-19 (Pascual-Ferrá et al), domestic terrorism (Piazza), and physical violence (Gallacher et al). Inversely, extremist violence has been suggested to be correlated with hate speech directed towards certain identities (Olteanu et al).
In order to study the long-term relationships between toxicity on SMNs and the ongoing political landscape, we propose a series of tracking continious trends on SMNs. Foremostly, we establish:
- A pipeline that randomly selects content from SMNs for analysis
- A machine learning model to classify toxicity
- A database to present trends and classified content.
II. Pipeline Implementation
We select Twitter are our initial choice of network, because of the relative popularity of research on Twitter as compared to other SMNs (Google Scholar Estimate: Twitter [N=7,940,000], Reddit [N=2,300,000], Facebook [N=7,180,000]. Accessed 5/27/2022), and the high accessibility of Twitter streams via API.
To measure toxicity on an SMN, we track the percentage of all available comments/tweets that are considered toxic. This provides an estimate of the proportion of toxic content a user will see if not influenced by content algorithms. Therefore our Twitter stream specifically includes retweets as a measure of the propagation of tweets.
Twitter's statuses/sample endpoint provides a real-time, random sample of Twitter's firehouse.
We then pass the Twitter stream through our Toxicity API to arrive at an automatic classification of content. Using an approximate API response time of 250 milliseconds, we estimate sampling 345,600 tweets, subject to fluctuation.
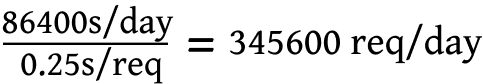
However, we then adjust for additional latency incurred by data storage and retrieval, bringing our per-tweet processing time to roughly 360 milliseconds, or 240,000 tweets a day.
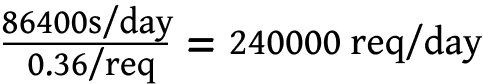
Finally, we store all processed data and text in a centralized, searchable database.
III. Text Processing
Prior to passing raw tweet content for predict, we perform several preprocessing steps:
- Replace user mentions with the @USER placeholder
- Replace URLs with the <http> placeholder
- Replace newlines and carriage returns with spaces
- Truncate multiple, extraneous spaces and spaces at line beginning and ends
- Standardize unicode character and quote encoding
These steps are automatically applied to text submitted to the Toxicity API.
IV. Toxicity API
Our Toxicitiy API relies on a natural language processing model to analyze text toxicity. We trained our dataset comprising of 293,822 individual, labeled comments sourced from previous-datasets, Reddit, Twitter, blogs, 4chan, and more. We then fine-tune several NLP transformer models with the transformers python library. Fine tuning involves secondary training of a model that has already been trained on a significant amount of generalized data to learn language syntax and vocabulary and is a form of transfer learning. Transfer learning with transformer models has been previously applied to produce state of the art results on common language benchmarks (ie, SST).
Therefore, we surmise that the best results can be acheived through applying transfer learning on our dataset. We experimented with fine-tuning the following models: BERT, ALBERT, DistilBERT, XLNet, ERNIE, DeBERTa, ELECTRA and RoBERTA.
From these results, we achieve the best cross-validated accuracy of ~97.92% on RoBERTA-large, followed by ALBERT-xxlarge-v2 (96.8% accuracy). Based on our extensive testing, we established that RoBERTA yielded significantly more accurate results as compared to ALBERT-xxlarge-v2.
For training, we selected a batch size of 16 and a learning rate of 6e-07 using a one-cycle policy.
We deploy the model via docker containers for maximum flexibility and scalability. We integrate deployment into our training process to ensure adjusted and tuned models can be re-deployed with ease. In general, we deploy new models every one or two weeks, adjusting data with new values to improve the confidence of true positives and reduce false positives.
To investigate and understand bias, we apply Jigsaw's Sentence Templates. We do find biases against the words, "homosexual", "Mohammed", and "transgender," that cause class-shifts. We will attempts to correct for these biases in upcoming model updates, though for our purposes, they are within acceptable tolerance denoted by the red and green lines respectively.
IV. Data Analysis
We present raw, hourly percentages on our Twitter Toxicity Index as a ratio of toxic tweets/all tweets in one hour intervals. Accounting for non-statistically significant fluctuations, we apply a twelve and twenty-four hour simple moving average.