Yesterday, you may have noticed that all API quotas were removed and set to unlimited. Thanks to some recent infrastructure upgrades, all users now have unlimited access to our API – for free. We’ve always targeted providing unlimited, unrestricted access to our moderation endpoints, but infrastructure capacity challenges make it difficult to do so.
Today, we’ve finally made it happen with the help of RunPod's Serverless Inference platform.
The many matrix operations crucial to machine learning mean models are most efficiently deployed on GPU (or dedicated IPU/TPU chips), a challenge to both source on a cost-effective basis and dynamically scale.
When we started out, we designed our backend architecture with the goal of bringing a functional product live as soon as possible, following a largely monolithic setup. Requests hit a frontend gateway that handled authentication and were routed to a single backend virtual machine that had our models loaded into the GPU and served requests.
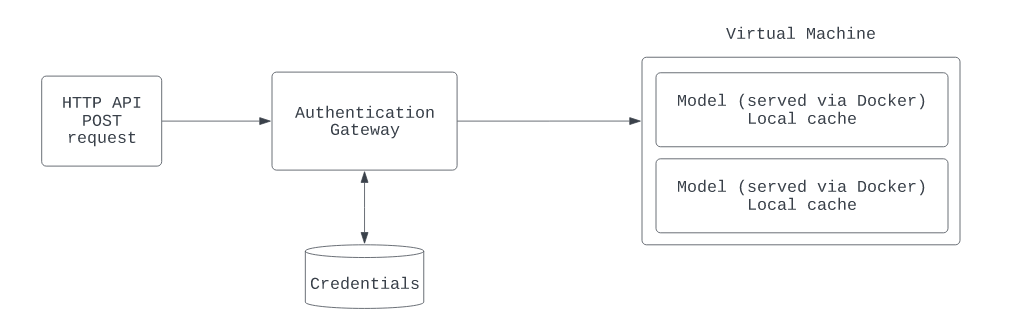
While relatively stable and fast when the host instance was not at capacity, there were several limitations within our existing setup that prevented us from scaling our setup horizontally in order to add additional capacity and improve resiliency to instance-level failures.
Thus, as our user base grew exponentially over the past few months and our data ingest volume ballooned to more than 10M+ comments a day, we started to look toward re-designing our infrastructure for greater elasticity.
As a nonprofit, we rely on the generous support of donors and grants to fund our ongoing costs – and infrastructure (especially GPUs!) is expensive.
And so, we needed a solution that would allow us to efficiently scale resources as demand changed, without sacrificing reliability or performance. But more importantly, we needed a solution that would be able to do this as cost-effectively as possible. As we talked with potential platform partners, Runcloud’s Serverless Inference Platform clearly fit the bill.
Their serverless platform is able to scale backed worker instances up and down dynamically, as capacity is reached – like Kubernetes, but better. Runpod automatically “warms” instances of our model to ensure that once a request is received, there is minimal delay and no need to wait for our machine-learning models to load into VRAM. With their platform, we get better flexibility, stability, and redundancy without having to manage Kubernetes clusters or ingress points and source host servers.
Today our infrastructure looks like this:

Despite the infrastructure overhaul required, the migration to Runpod’s platform was surprisingly simple. They deploy via docker containers, which we already use, and the support from their team throughout the process has been nothing but exceptional. The entire deployment to production took less than five minutes, and we saw absolutely zero downtime or transient errors during the process.
Since switching to the RunPod Serverless Inference platform, we've already doubled our current daily data ingest volume and more than tripled our active stand-by capacity. We’ve also seen a 40% reduction in endpoint error rates and a 60% drop in p-99 response times. This additional capacity has helped us drastically decrease our comment-processing backlog, allowing us to detect hate within our online community partners significantly faster than before and take action.
We're excited to continue our partnership with RunPod and can’t wait to see what the future holds!